Sprache ist für unsere Kommunikation essenziell – entsprechend schlimm ist es, wenn Menschen durch Krankheit oder Verletzungen die Fähigkeit zu sprechen verlieren. Dies tritt häufig bei Schlaganfällen auf, aber auch bei neurodegenerativen Erkrankungen wie Parkinson, Alzheimer und der Amyotrophischen Lateralsklerose (ALS) verlieren Patienten mit fortschreitender Krankheit die Kontrolle über ihren Sprachapparat. Bisher blieb den Betroffenen in extremen Fällen nur eine Kommunikation über computerisierte Buchstabentafeln, bei denen Augenbewegungen den Cursor auf die gewünschten Buchstaben steuern und daraus dann synthetische Sprache produzieren. “Diese Systeme können die Lebensqualität der Patienten erhöhen, aber viele Nutzer schaffen damit kaum mehr als zehn Wörter pro Minute – das ist weit langsamer als die 150 Wörter pro Minute der natürlichen Sprache”, erklären Gopala Anumanchipalli von der University of California San Francisco und seine Kollegen.
In zwei Schritten vom Hirnsignal zur Sprache
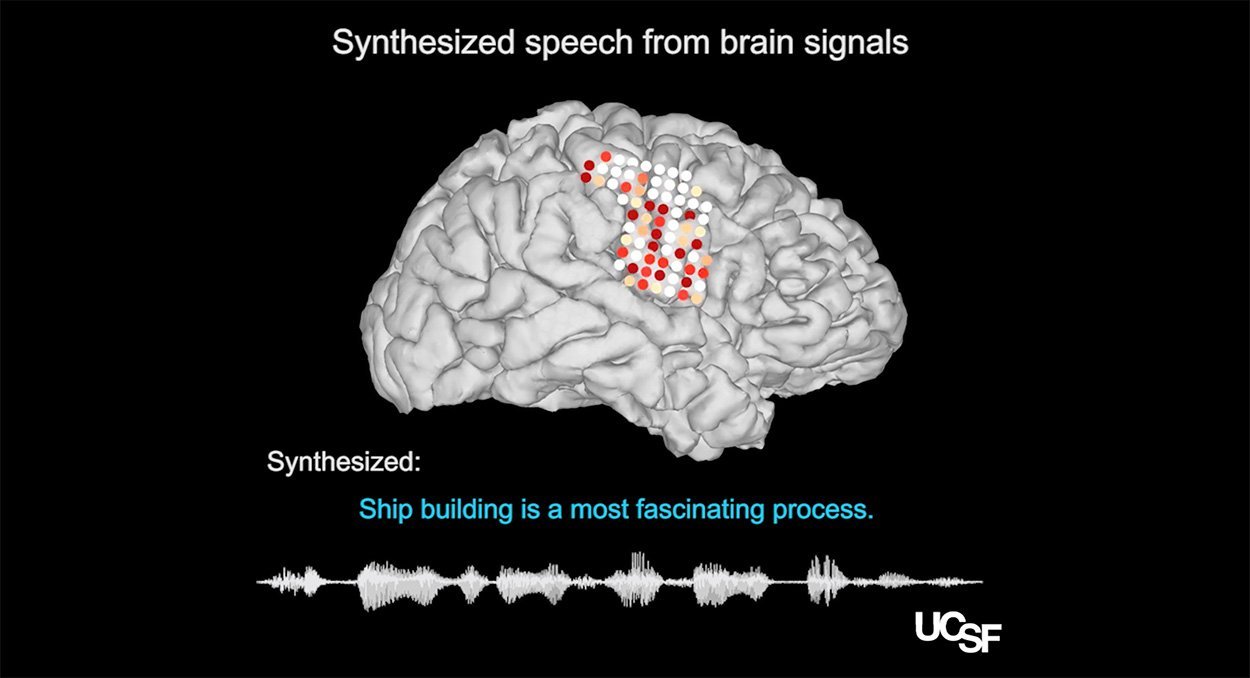
Schon länger versuchen Neurowissenschaftler deshalb, eine direkte Schnittstelle von gedachten Wörtern zu gesprochener Sprache zu entwickeln. Dafür werden die beim Denken von Sprache erzeugten elektrischen Aktivitätsmuster des Gehirns ausgelesen und dann über spezielle Computersysteme in akustische Wörter und Sätze umgewandelt. Bisher jedoch liefern Prototypen nur wenig verständliche Sprachausgaben. Deshalb haben nun Anumanchipalli und sein Team für ihr System einen etwas anderen Ansatz gewählt. Statt die Hirnsignale von gedachter Sprache direkt in akustische Spektrogramme zu übersetzen, konzentrierten sie sich auf die Hinströme, die mit der komplexen Steuerung der Mund- und Kehlbewegungen beim Sprechen verknüpft sind. In einer früheren Studie hatten die Forscher bereits entschlüsselt, welche Hirnsignale für die komplexe Kontrolle des Sprechapparats zuständig sind.
“Die Verbindung zwischen den Bewegungen des Sprechapparats und den Sprachlauten, die von ihm produziert werden, ist sehr kompliziert”, sagt Anumanchipalli. “Aber wenn die Sprachzentren im Gehirn eher diese Bewegungen steuern als die direkten Laute, dann sollten wir versuchen, das Gleiche beim Dekodieren dieser Signale zu tun.” Um das zu erreichen, nutzten die Forscher zwei neuronale Netzwerke – lernfähige Systeme, die jeweils einen Teilschritt des komplexen Ablaufs übernahmen. Das erste war darauf trainiert, Hirnsignale der Sprachzentren in Bewegungen eines virtuellen Sprechapparats mit Zunge, Lippen, Gaumen und Kehlkopf umzusetzen. Das zweite neuronale Netzwerk setzte dann die Bewegungen des virtuellen Sprechapparats in akustische Spektrogramme um, die dann vom Computer als gesprochene Wörter und Sätze ausgegeben wurden.



